How I Built an AI-First Knowledge System That Actually Works
The system that turned my scattered expertise into a compound competitive advantage

Most knowledge management systems fail for one simple reason: they're built for storage, not retrieval.
You capture everything. Index religiously. Tag meticulously. Then when you need that brilliant insight from three months ago?
You stare at a search bar, hoping keywords will surface gold from your digital haystack.
After multiple failed attempts with different systems, I just built what I call my personal "context engine.” It’s an AI-first knowledge system that doesn't just store ideas but actively synthesizes them into actionable intelligence.
I've only been using it recently, but it already feels transformative. It just works.
Like having JARVIS from Iron Man as my personal chief of staff, maintaining my growing knowledge base and keeping me strategically aligned.
Here's how it works and why it might be the productivity breakthrough you've been searching for.
The Genesis: Three Failed Systems and a Breakthrough
Like most knowledge workers, I've tried every system. The promise was always the same: capture everything, organize perfectly, retrieve effortlessly. The reality? My insights lived scattered across systems that never quite worked.
Iteration 1: Obsidian + Google Drive + Cline + RAG Experiments
This was a very simple system I tried in Janary/February when I first started tinkering more intently with LLMs and other parts of the AI stack. I started with local files in Obsidian (a visual note taking tool), integrated with Google Drive and using Cline (open-source AI agent in VS Code) for AI assistance. I even built a simple embeddings RAG and trialed NotebookLM.
Great for single topic retrieval and studying, but not great for evolving understanding. As my knowledge on topics changed over time, I'd get muddled with conflicting information on the same subject. It didn’t have temporal awareness. Also, NotebookLM is purely retrieval-based, not conversational or oriented towards actively creating new ideas. The citations were distracting, pushing me to find other sources rather than reasoning with me in the moment.
Also, the UX of this setup just wasn’t fun to use.
It’s hard to quantify, but it counts. I was using Google's 1206/Flash 2.0 Thinking model, solid intelligence at the time but not the best for an agentic experience; its capability as an agent and iterative tool calling wasn’t great.
No web search integration meant limited ad-hoc retrieval. Files kept fanning out into chaos. The system just felt like it always veered a bit off from what I wanted.
I never stuck to it.
Iteration 2: Airtable + MCP + Web Search
Thinking I needed more structure, I tried Airtable with Claude Desktop plugged into an MCP Server for database-like retrieval. Finally got web search integrated as an MCP too natively.
It worked exactly as intended for storage, but new problems emerged. I would use Claude to draft and it worked great to store things into Airtable, but I’d always have to move the content and draft it somewhere else (I wasn’t drafting in an Airtable database cell). That created retrieval friction.
Also, the structured SQL-like search was too literal, returning everything matching my query and flooding the context window. I either had to pull way too much, or didn’t get enough.
Worse, with web search added, it would really sway Claude. Web results significantly skewed the generation toward those sources. I couldn't trust it to blend well with my own previous insights and external data overpowered my accumulated knowledge. Reliable retrieval, but I got noise I didn't want alongside what I needed.
I stuck with it, but it wasn’t all that helpful.
Iteration 3: The Natural Breakthrough
The current system just feels GOOD. The magic? Claude Code.
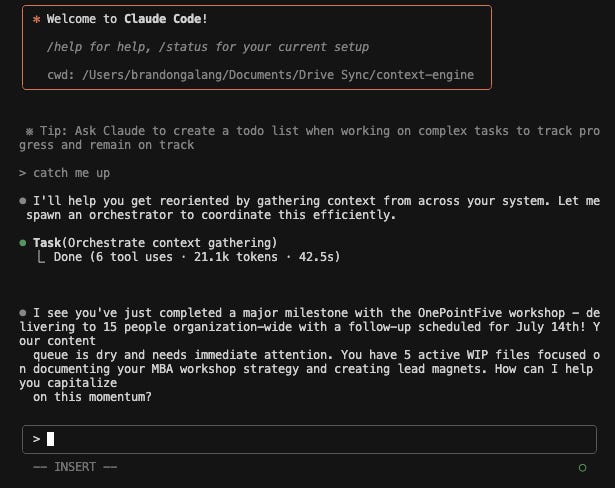
If you aren’t aware, Claude Code is an agentic tool Anthropic released a while ago. They recently added subscription access. Previously, they required users to pay directly via their API rates.
Claude Code is the same Claude, but with WAY less guardrails and restrictions. It also has much more tool access, most notably, the ability to spawn Claude sub-agents that it can use to execute tasks for it. This allows a top-level orchestrator Claude agent that you interact with to delegate work to other agents, sometimes in parallel, to accomplish tasks.
Rather than search with SQL or rely on embeddings, Claude can have OTHER Claude agents crawl across files, synthesize data, and return a summarized report. Agentic search with intelligent context isolation. Delegating organization, retrieval, context management, everything to Claude.
Here is a little visualization, brought to you courtesy of Gemini 2.5 Pro’s Canvas tool:
The best part of building this system was as I was using it, I realized I wanted other things and I asked Claude to update the system for me. I realized I wanted an inbox of “top of mind” things to reference and work on so I didn’t have to start from scratch. I wanted places where I could re-orient myself and also centralize key context I wanted to feed Claude.
For the first time, I don't have to change how I work. The system adapts to me.
Everything else gets logged and archived by AI agents in the background. Claude dynamically updates, reorganizes, and optimizes while I focus on what's absolutely top of mind.
The breakthrough insight: don't organize information for humans to browse.
Organize it for AI to process and synthesize on demand, but give humans simple, clear interfaces for the things they actually need to see.
Want to give the context engine system a try?
If you’re interested in trying out this system, I made a prompt to help you initiate it’s basic structure that you can download here.
Why Traditional Knowledge Management Dies
Before diving into the solution, let's acknowledge why every other system you've tried eventually becomes digital clutter:
The Browsing Fallacy
Traditional systems assume you'll remember enough context to browse your way to insights. Reality: you remember problems, not file hierarchies.
The Perfect Organization Trap
You spend more time categorizing than creating. The system becomes work instead of enabling work.
The Context Collapse
Information without situational context is just data. Most systems strip away the why, when, and how that makes knowledge actionable.
The Single-User Bottleneck
Your brain becomes the only processor that can connect dots across your knowledge base. This doesn't scale.
The context engine solves all four problems through intelligent automation and AI-first design.
The System: How the Context Engine Actually Works
The system I built is very simple. It’s literally just a folder of folders of text files. However, in the world of AI, especially agentic AI, text is code.
Just like you use prompts to direct ChatGPT or Claude, I have key files that serve as conditional prompts that Claude Code can access to find instructions on how to operate my system.
To keep it simple, think of this as a personal chief of staff that never forgets and actively synthesizes your knowledge.
Layer 1: Frictionless Capture
The Rule: If capturing an idea takes more than 30 seconds, it won't happen consistently.
My capture system has multiple entry points, all designed for zero friction:
-Active folder: Where I draft and work on current projects
-Inbox folder: Quick capture via Google Drive when I'm on my phone or away from Claude to be processed later (… By Claude)
Direct to Claude Code: Transcripts and raw thoughts fed directly during work sessions
Logs: Claude automatic captures all significant actions and decisions and logs it
Don't organize during capture. That's future-you's job, aided by AI that can process context at machine speed.
Claude handles the synthesis and organization later. As long as it gets captured, Claude will properly organize it no matter what it looks like.
Layer 2: Multi-Layered Memory Architecture
The Challenge: Human memory is associative, but file systems are hierarchical.
The engine maintains multiple interconnected memory layers:
1) Active Work
Current projects and drafts I'm actively thinking about
2) Inbox
Temporary captures from mobile or quick thoughts (for Claude to index later).
3) Reference Knowledge
Strategic documents structured for human review if needed. More static context to prompt Claude.
4) Claude Memory
14-day rolling context of patterns and decisions for Claude to recall our recent interactions. Archived after 14 days.
5) Daily Activity Logs
Complete source of truth for all edit actions.
6) Long-term Vault
Completed work.
7) Obsidian Canvas
Here’s an element I retained from experiment 1 that grows even more effective in this system. As I work in this system, Claude can maintain the Obsidian mindmap and main file to file relationships (file X inspires Y, file A drives B, etc).
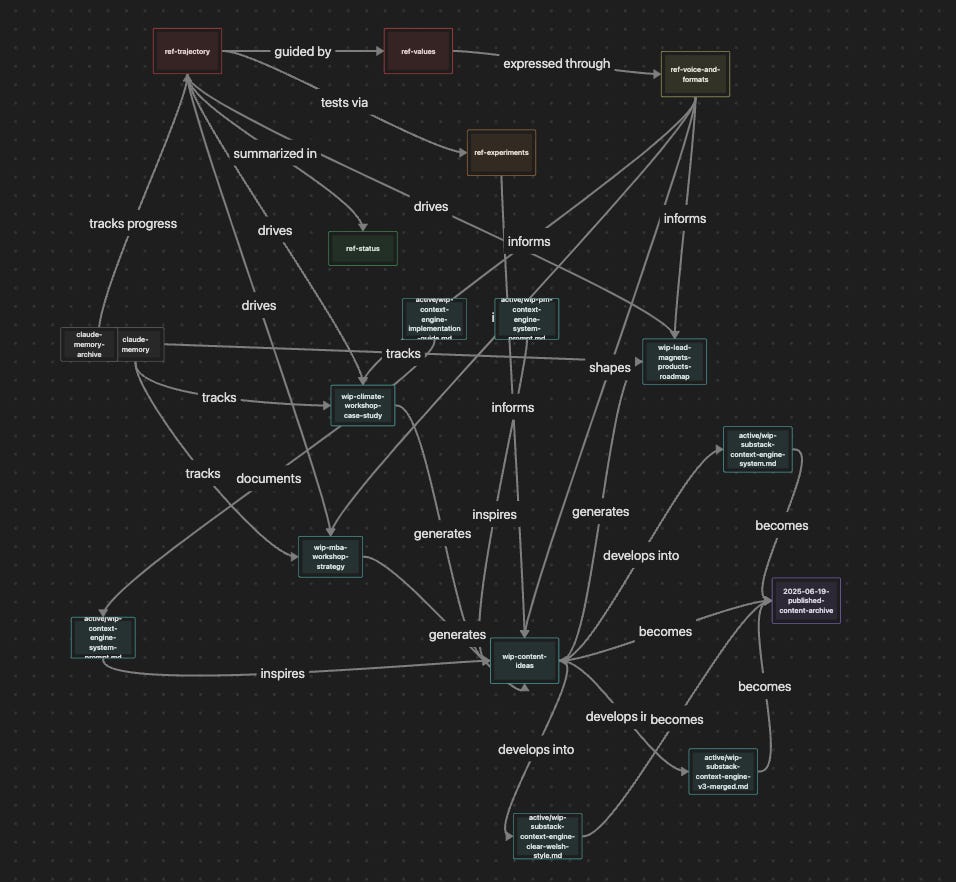
The coolest part? Claude can use these file to file relationships to quickly understand relationships and find relevant context faster.
Now, you might be thinking this is a lot of memory. How does Claude read all this? Even if you have multiple agents, doesn’t this just BURN tokens?
The key to all this: not everything loads at once.
The `CLAUDE.md` file acts as the orchestration manual, telling Claude how to selectively retrieve only what's needed for the current task. Instead of flooding the context window with everything, sub-agents fetch specific pieces based on what you're actually doing.
When I ask Claude to get started and caught up from a cold start, it creates 7 sub-agents that fan out and read its memory file, my trajectory reference file (my goals and recent progress towards them), my values, my WIP files, my recent activity logs, my Todoist tasks (via MCP server).
These seven agents then feed their report back to ANOTHER agent, which synthesizes all their disparate reports, and gives it to the top-level agent I interact with.
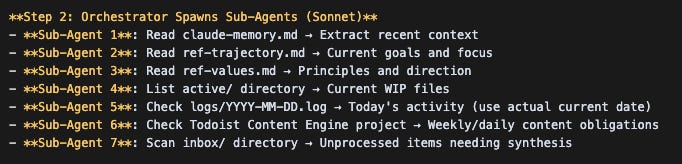
Near perfect synthesis without diluting its context window. I don’t do this all the time as it does take a minute or two for Claude to complete. But it’s VERY effective when I want to get re-oriented.
I can take a similar approach when I want to begin writing on a topic I know I have prior thinking and writing on.
For example, when planning content strategy, Claude draws from completed posts in the vault, active experiments in reference files, recent patterns in claude-memory, and current drafts in active, all without me having to remember where anything lives.
Layer 3: Active Intelligence
This is where magic happens. Instead of passive storage, the can intelligently reason about all this generated context and actively improve over time.
I’m planning on automating this pattern, but right now I can ask Claude Code to review all the workspace and generate the following types of insights:
Pattern Recognition
"You've mentioned 'expert amplification' in four different contexts this week"
Strategic Alerts
"This idea conflicts with your stated goal of simplifying client onboarding"
Connection Synthesis
"Your March insight about constraint theory could solve today's workflow problem"
Progress Tracking
"You're 70% through your Q2 content goals but haven't touched the lead magnet project"
We now have a system that can provide intelligence and functionality that you didn’t design into it, but instead emerges from the context you’re already generating by documenting your work.
This is how you build loops of compounding leverage.
Layer 4: Strategic Guidance
The system doesn't just remember, it advises. Built around my core values and strategic direction, it acts as an always-on strategic thought partner.
Values Alignment
Every recommendation gets filtered through documented principles. The system knows I optimize for systematic thinking over ad-hoc solutions, so it flags when I'm solving symptoms instead of root causes.
Decision Support
Complex choices get evaluated against past similar decisions, likely outcomes, and strategic fit.
Momentum Maintenance
The system tracks energy patterns and suggests work that aligns with current capacity and focus.
The Complete Architecture: Every Layer Working Together
Here's the full system architecture that makes this magic happen:
Core Memory Layers
1. Reference Files (Human Interface)
- `ref-trajectory.md`: My north star, where I keep my current goals, active projects, completed wins
- `ref-values.md`: Core principles that guide every decision
- `ref-status.md`: Weekly executive summary auto-generated from logs
- `ref-experiments.md`: Active tests with hypotheses and results
- `ref-voice-and-formats.md`: 30+ content templates and voice guidelines to help me draft content
2. System Memory (AI Working Files)
- `claude-memory.md`: 14-day rolling context of key conversations and patterns
- `CLAUDE.md`: The system's operating manual, this is how Claude acts as my chief of staff and knows how to interact with everything else
- `context-engine-design.md`: Architecture doc of the system as it exists today so I can refer back to it and improve upon it
- `main.canvas`: Visual knowledge map showing relationships between concepts
3. Active Workspace
- `active/`: Current work-in-progress (max 20 files, touched in last 14 days)
- `inbox/`: Quick capture for mobile/away from Claude, processed asynchronously
Everything here is fluid, meant to be worked on and evolved.
4. Long-term Storage
`vault/`: Completed work archived with dates (YYYY-MM-DD-[slug].md)
`logs/`: Daily activity logs that serve as source of truth
Despite so many distinct layers, the beauty is that all I have to think about are the handful of my reference files and my active folder where I keep my drafted work. Everything else just works. Claude maintains the rest. When I want tweaks, Claude refines the architecture for me.
Real Results: What This Actually Enables
Rapid Strategic Reorientation
When I need to quickly assess my content strategy across multiple platforms, I query Claude once. Instead of opening dozens of files and trying to remember what I'd tried before, I ask the system:
I’m feeling a bit scattered. My friend reached out about Project X and I’m thinking about doing that and I think I’ll write about Y for my Substack on Sunday. Help me get back on track.
The system synthesizes:
- High level context from its short-term memory
- Strategic goals from my trajectory document
- Recent activity from the system logs
- Items from my Todoist task lists
- What’s currently in my /active folder
Result:
“Project X is interesting as it supports your goal of Y, but it conflicts with your stated objective Z that is gaining momentum and traction and your desire to emphasize sustained focus.
I recommend completing your WIP work before taking on other commitments.
You can write about Y and incorporate elements of your recently drafted post on Karpathy’s AI Startup School talk for Sunday. Do you want me to create an outline?”
Clarity in a single query.
The Implementation Framework: How to Build Your Own
You don't need to rebuild my exact system, but you can apply the principles to whatever tools you're already using.
Phase 1: Audit Your Knowledge Chaos (Week 1)
Map your current information ecosystem:
- Where do ideas currently go to die?
- What knowledge do you recreate instead of reusing?
- Which decisions would benefit from historical context?
- How much time do you spend searching vs. creating?
Phase 2: Design Your Capture System (Week 2)
Pick ONE primary capture point, but learn from my mistakes.
Avoid the Organization Trap
Over-structured systems feel like work. If you're dreading inputting information, you won't capture consistently.
Find The Sweet Spot
Simple file system with AI-assisted organization. I use a context-engine folder with clear subdirectories (active/, vault/, logs/) and let Claude handle the complex organization.
The key is consistency, not perfection. But choose a system that feels effortless to use daily and integrates smoothly with AI. Maybe that’s Notion AI, maybe that’s a single Google Doc that you can easily dump into Gemini. Maybe it’s an pinned Gemini chat that acts as your executive assistant.
Find something you can easily use every day and adds value every time you touch it.
Phase 3: Implement AI-Assisted Processing (Week 3-4)
This is where most people skip ahead, but don't. You need data before you can process it intelligently.
Start with simple AI assistance, perhaps in a single consolidated chat. I recommend Gemini for long threads. Use it to:
- Weekly review prompts that help you identify patterns
- ChatGPT sessions that help organize and connect ideas
- Simple automation that adds metadata to your captures
Find reliable, repeatable ways to add clarity that don’t push you down different rabbit holes.
Phase 4: Build Your Strategic Layer (Ongoing)
Document your values, goals, and decision frameworks. This becomes the AI's strategic context for recommendations.
Create templates for:
- Decision documentation
- Project post-mortems
- Weekly strategic reviews
- Pattern recognition exercises
Here is where you move beyond simple ad-hoc queries and find ways to synthesize larger bodies of context to get deeper insights.
Phase 5: Scale and Systematize (Month 2+)
Once the basics work consistently, layer in more sophisticated automation:
- Auto-categorization of inputs
- Proactive synthesis of related ideas
- Strategic alerts and reminders
- Cross-project pattern recognition
If you want to shortcut this, start with Claude Code from day 1. Remember though: even if Claude Code can maintain your system for you, you still need to build the habit of engaging with it.
Claude Code is incredible, but it’s not your parent (… yet). You need to build the discipline to engage yourself, no matter how little friction there is in using the system.
The Compound Effect: Why This Changes Everything
Traditional productivity focuses on doing more things faster. The context engine enables doing better things by leveraging everything you've already learned.
Every interaction improves future interactions. Every insight captured becomes available for future synthesis. Every decision documented informs future choices.
I don't just have better productivity, I have compound intelligence. This is a Leverage Loop. My knowledge base actively makes me smarter and more strategic over time.
Your Next Action
If this resonates, don't try to build everything at once. Pick one pain point from your current knowledge management chaos and address it systematically.
Start with capture. Everything flows from there.
The goal isn't perfect organization, it's compound intelligence that makes you more effective every day. It’s building your very own Leverage Loop.
Your expertise deserves a system that scales with it.
- Brandon
Hey Blair, glad you liked it. I've iterated on it a few times. I am testing a product for a team that is building a more formal UI and the ability to swap and use faster models like Kimi K2 or Gemini 2.5 Fast Lite for broad search and reorganization is really nice.
Incredible, well done and thanks for sharing! How is it going today? Have you evolved this any further? I'm just in the trenches with making something that works for me, getting there but this blog is really helpful thank you.