How I Built a PE Fund Matching System in a Weekend: The Complete Build Journey
In the AI era, domain expertise is optional, what matters is knowing how to learn and deploy those learnings

This is the story of how I built this:
TL;DR
The Challenge: Build a system to match companies with PE buyers The Twist: I knew nothing about private equity The Insight: In the AI era, domain expertise is optional, what matters is knowing how to learn and deploy those learnings
What You'll Learn
How to break down complex problems in unfamiliar domains using AI
The two-stage retrieval pattern that makes matching systems actually work
Why "good enough" beats perfect when building on weekends
How an industrial engineering mindset applies to AI systems
Actual prompts and techniques for building with AI as your partner
The Start of the SMB - PE Matching Rabbithole
Ever have one of those Friday nights where you're looking at your weekend project list and decide to tackle something completely outside your comfort zone?
That's exactly what happened to me two weekends ago.
I've been on a bit of a building streak, testing how far I could push AI-assisted development. Each weekend, I've been picking something more ambitious.
This time, I was staring at a completely foreign concept: PE fund matching.
The problem fascinates me. Companies spend years building value, then when they're ready to exit and retire, finding the right PE buyer is basically playing darts blindfolded while someone charges you six figures for the privilege. It's inefficient, opaque, and ripe for disruption.
Here's the thing though; I know absolutely nothing about private equity. I couldn't tell you the difference between growth equity and buyout if my life depended on it.
But that was kind of the point. Could I go from complete ignorance to working system in 24 hours? There was only one way to find out.
I opened my laptop and thought: "Let's see how deep this rabbit hole goes."
Spoiler alert: It went deep.
And what I discovered about building with AI as a thinking partner changed how I approach every project since.
The Problem That Started Everything
Let me paint you the picture of why this problem is so fascinating. From what I'd read, the current process of selling a company is absolutely medieval.
If you want to sell your company, you basically have three options:
Option 1: Hire an investment banker who charges a massive retainer plus percentage (their "proprietary database" is usually Excel sheets from 2003), but most SMBs really aren't worth it for most banks so this isn't usually the move
Option 2: Try DIY with cold emails based on Google searches (good luck with that)
Option 3: Know someone who knows someone (how most deals actually happen)
The inefficiency is staggering. The perfect buyer might be out there, some fund that would pay a premium because your company fits perfectly with their thesis. But if they're not in your banker's Rolodex, you'll never find them.
That's when it clicked for me. This isn't a relationship problem. It's a data problem disguised as a relationship problem.
And data problems? Those I can solve.
Well, theoretically. I still knew nothing about PE. But that was about to change.
Friday Night: Becoming a Domain Expert in 60 Minutes
Here's the thing about being a builder in the age of AI. The most interesting problems are often in domains you know nothing about. Five years ago, that would have been a dealbreaker. Today? It's just another constraint to work with.
I got home around 9 PM, opened my laptop, put on Squid Games season 3 on Netflix in the background, and started with the most basic prompt I could think of:
"I want to build a system that takes a company and finds PE funds that would be good buyers. I know literally nothing about private equity. Help me understand what this actually entails."
What followed was one of those magical conversations where AI becomes your tutor.
Claude started explaining the basics, and I kept pushing for more detail.
The Questions That Unlocked Understanding
The conversation went something like:
Me: "What does 'growth equity' actually mean? Like, specifically?"
Claude: Explains it's not just about size but a specific lifecycle moment
Me: "So they want companies that have already proven they work?"
Claude: Details about product-market fit, scaling needs, not turnarounds
Each answer opened up new dimensions:
What's the difference between growth equity and buyout?
How do funds think about geographic focus?
What does "platform investment" mean versus "add-on acquisition"?
After about 30 minutes, I had developed a mental model of how PE funds think about investments. Was I an expert? Hell no. But I understood enough to build something useful.
The Critical Insight: Asymmetric Information
This is where bringing in a heavier reasoning model paid off. I fed it everything I'd learned into o3 Pro (cheap access via Genspark! o3 Pro is great but not sure if it's worth $200/month) and asked:
"Help me think through the technical implications of building this matching system."
The response stopped me cold:
"The fundamental challenge here is that you're dealing with asymmetric information availability. You have millions of potential target companies with limited public information. But you only have thousands of PE funds, and they're required to disclose significant information through regulatory filings."
That changed everything. I'd been thinking about this as one matching problem. But it was actually two completely different data problems:
Companies: Need real-time intelligence gathering (can't pre-index every business)
PE Funds: Can build comprehensive database (finite universe, stable data)
This kind of insight is what makes AI such a powerful thinking partner. I would have eventually figured this out, probably after wasting hours building the wrong thing. Instead, I got there in the first hour.
Building the Company Intelligence Layer
With the problem properly decomposed, I decided to start with the company side. This is where things got practical and messy in the best way.
The Research Agent Architecture
My first instinct was to build something complex. Web scrapers for every business data source, APIs for financial data, maybe some PDF parsing for pitch decks. Classic over-engineering.
Then I caught myself. What's the simplest thing that could possibly work?
I turned back to Claude:
"I need to build a research agent that can gather intelligence on any company. It should search the web, but be smart about what to look for. What's the minimal architecture that would actually work?"
The response was beautifully simple: "Think about how a human analyst would research a company. They'd start with a broad search, see what they find, identify what's missing, then search for specific gaps. You can implement this as a simple loop."
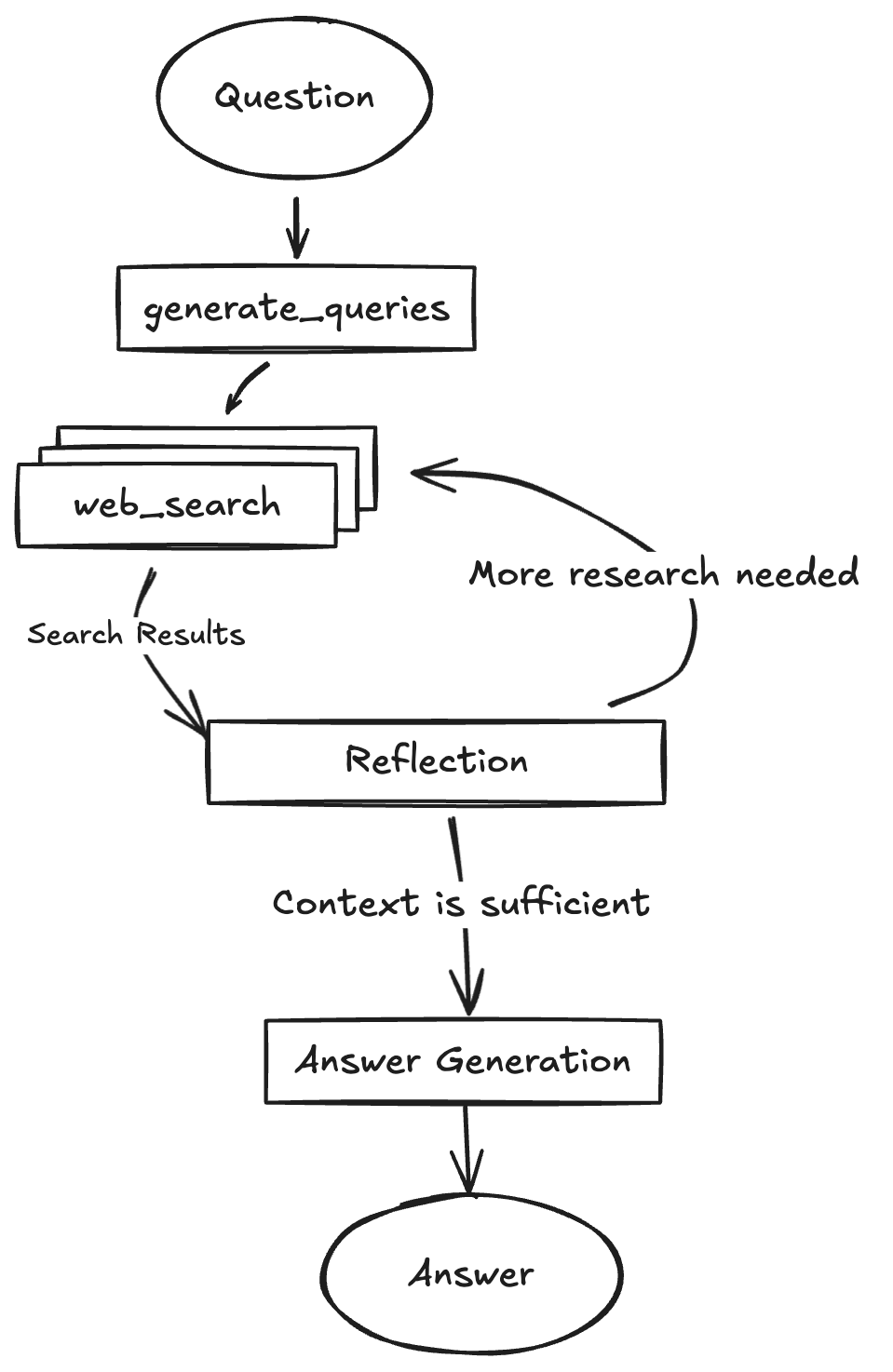
Of course. I didn't need complex orchestration. I needed a loop that mimicked human research behavior.
From Theory to Implementation
The actual build was where AI pair programming shines. Instead of writing boilerplate, I could focus on logic:
"Hey Claude, please set up a basic PydanticAI agent with Gemini 2.5 Flash. Look up the documentation and do it. I want a simple agent with a web search tool using Gemini's native web search grounding."
Now, I had already done some tinkering with AI agent frameworks earlier in the year so I knew to ask for PydanticAI. If you didn't have that experience, you could've gotten to that asking Claude "what's the simplest way i can built an agent that can search in a loop?"
The implementation ended up elegantly simple:
Search for company basics
Evaluate what was found
Identify gaps
Search for specific missing pieces
Repeat until confident
This looked like a single agent with a prompt to use the search web tool until it found enough data to output the required data I needed (detailed below). If it couldn't find it after a few searches, it would end the search and output what it had. The agent would adapt based on what it found. If it discovered a SaaS company, next searches would target ARR, churn rates, customer concentration. Manufacturing company? Look for capacity utilization and contracts.
Getting the Data Model Right (Now and In the Future)
Ultimately, I settled on a minimum set of data related to the data I was able to find on the PE funds (again, detailed below). However, here's a simple framing for how this system could progress from simple to sophisticated:
Iteration 1 (Naive):
Company name, industry, employee count
Result: Useless for acquisitions
Iteration 2 (Better):
Added revenue, growth rate, basic financials
Result: Still missing crucial elements
Iteration 3 (Getting Smart):
Added "soft factors": leadership backgrounds, culture indicators, strategic changes
Result: Now we're getting somewhere
Iteration 4 (PE-Ready):
Added "readiness signals": Recent leadership changes (new CFO = preparing for sale?) Growth inflection points (found their secret sauce?) Customer concentration metrics (PE funds hate concentration risk)
Result: Actually useful for matching
Each addition would come testing and thinking: "What would a PE fund actually want to know?"
If I were actually building this for business, I'd interview some PE folks too.
Saturday Afternoon: The Fund Data Revelation
Now came what I thought would be the hardest part: getting comprehensive data on PE funds. Commercial databases charge tens of thousands per year. Scraping would be extremely costly time-wise and while the API fees would be less than data APIs, still non-trivial.
But I had a hunch this data might be hiding in plain sight.
The SEC Form ADV Discovery
I went to Gemini Deep Research and effectively fired off this query:
"Please do research on free databases or datasets on private equity firms focused on small and medium sized businesses in the united states."
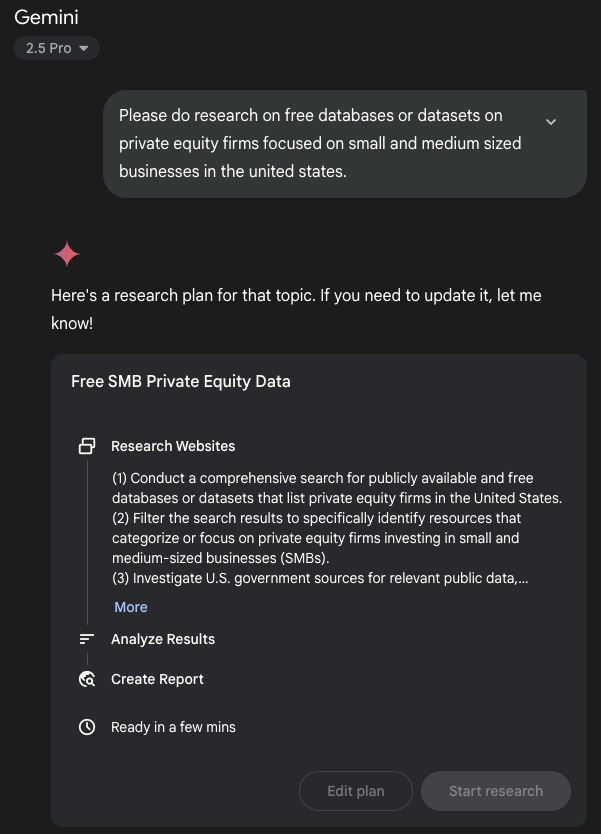
A few minutes later, I had everything I needed.
It did find a number of expensive data sources, but also found another viable dataset. The SEC requires all investment advisors to file Form ADV, a master disclosure document every U.S. investment adviser must file. It provides structured data on ownership, AUM, fee types, custody arrangements, service codes, etc. It also includes plain-english narrative on services, investment strategies, fees, conflicts, etc.
All public. All machine-readable. No scraping needed.
I spent the next 15m downloading ADV data and getting ready to feed it to Claude Code.
The Data Engineering Reality Check
Of course, finding the data was just the beginning. The ZIP files I found were packed FULL of different CSVs.
Sorting through this manually would have taken forever.
This is where AI-assisted development really shines.
"Here's a sample of raw ADV data. Help me design a clean schema for PE fund data and build parsers for each field. Also, the strategy descriptions are freeform text. Can we extract structured information like sector focus and check sizes? Please look through the files in the folder and propose a plan."
Claude Code handled it all flawlessly.
Identified what data was ACTUALLY in the CSVs and what we had to work with, confirming I could move onto the next step.
The Database Architecture Decision
With data sources figured out, I faced a crucial decision. How do you build fast, intelligent matching between fuzzy company profiles and fund criteria?
The Options I Considered
Option 1: Pure SQL
Pros: Fast, deterministic for hard criteria
Cons: Can't handle "funds interested in this type of company"
Option 2: Pure Vector Search
Pros: Great semantic matching
Cons: Might recommend a $100M+ fund for a $10M company
Option 3: Pure LLM
Pros: Nuanced understanding
Cons: Expensive, slow, unreliable at scale
The Hybrid Solution
Why choose? The two-stage architecture:
Stage 1: Vector search for semantic similarity - Embed fund data in the database and retrieve the "vocabulary" that can drive a more precise retrieval later (~200 funds)
Stage 2: SQL filters + LLM analysis - Apply hard constraints (check size, geography, stage) to gather a list of "viable" PE funds, then narrow to 20-30 funds with LLM analysis on the shortlist for "last mile" reasoning
This gave me the best of all worlds: fast retrieval, hard constraints, and nuanced analysis.
This also drew upon prior experiments with RAG retrieval (structured data vs vector embeddings), but you could have gotten here by asking "How can I store this ADV data for quick retrieval? What are my options?" and continuing to drill down.
The Magic of the Analysis Layer
My engineer brain wanted to create a complex scoring algorithm. I spent some time going back and forth with Claude building this elaborate scoring system with weights and formulas based on the ADV data and the SMB data my research agent retrieved.
However, I paused and took a very different approach when I realized this was overkill.
The Analysis Realization
When you aren't able to get hard, validated, trusted data, does it even make sense to use a rigid quantitative scoring mechanism.
If somebody were to actually use this tool, it would be an augmentation on their own judgment. This would simply be a tool to guide a much longer, extended process.
So why was I trying to replace judgment with rules? Why not augment it instead?
I'd already used reasoning models with loose context to great effect so often in my own work.
I scrapped the scoring system and tried something different:
"Analyze this company-fund match like a senior PE professional would. Focus on strategic rationale, potential synergies, concerns or red flags. Narrow down to the top {top_k_candidates} funds and output a report on your ranking and reasoning."
The results were fantastic. I asked Claude Code to output the analysis into a report in the terminal. Here's what I got.
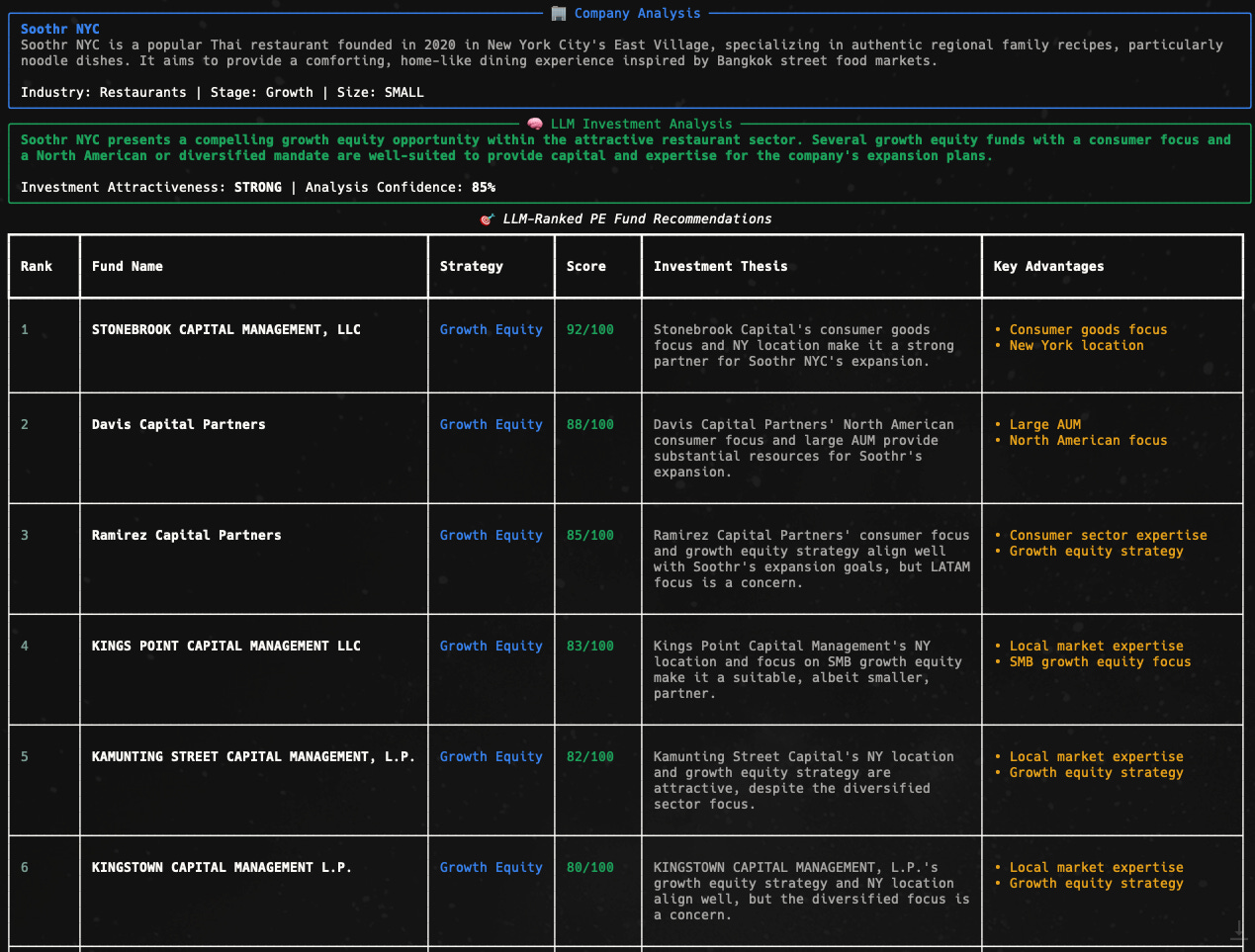
This concluded my build experiment.
The Industrial Engineering Lens: Scaling Human Reasoning
Here's what most developers miss: AI systems aren't about replacing humans. They're about expanding human bottlenecks.
The Real Bottleneck is the Person
Without this system, someone searching for PE buyers faces severe constraints:
They can manually research maybe 20-30 funds
They're starting from their existing network or basic Google searches
They're analyzing based on surface-level criteria
They simply don't have time to deeply evaluate hundreds of options
This system changes the equation.
It leans into what AI is good at; processing vast amounts of unstructured data and creating smart inferences against a targeted prompt.
Instead of a human trying to research, analyze, and match across thousands of funds, they can focus on what humans do best: relationship building, strategic thinking, and final judgment calls.
Why "Good Enough" is Actually Better
From an industrial engineering perspective, this is a fuzzy process by nature. We're not solving for mathematical optimality, we're solving for better decision support.
Consider what really drives these deals (especially if you lacked the hard quantitative numbers):
Personal chemistry between founder and fund partners
Timing and market conditions
Strategic fit that goes beyond checkboxes
Trust and relationship dynamics
No algorithm will capture whether a founder "just likes" the fund partner. And that's fine! We're not trying to. We're trying to surface options that would never have been considered otherwise.
The Reliability Paradox
Here's the counterintuitive insight: AI's "non-determinism" isn't a bug in this system, it matches the problem domain.
When an agent researches a company, it might find slightly different information each time. So what? A human researcher would too. What matters is:
Consistently high-quality reasoning within the context window
Comprehensive coverage of the search space
Transparent explanations of the logic
We're already seeing AI systems SIGNIFICANTLY outperform doctors in diagnoses when given sufficient context.
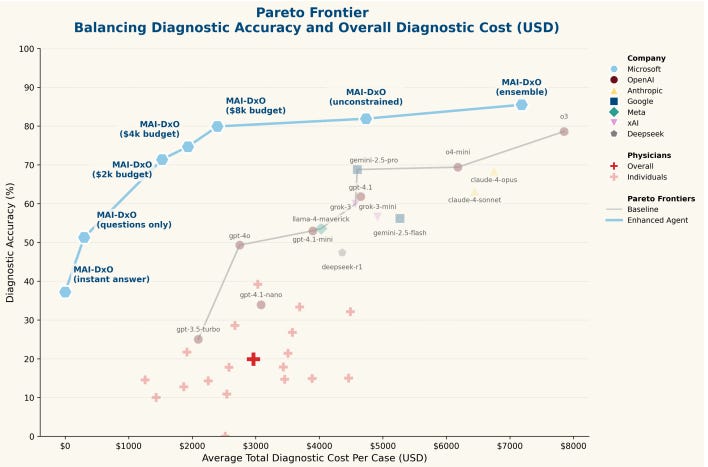
This PE matching system is just another instance of the same phenomenon: given ample data and reasoning capability, AI can provide insights that augment human decision-making in powerful ways.
The system doesn't need to be perfect. It needs to be better than the alternative.
The Meta-Learning: What Building With AI Really Means
As Sunday evening approached and I put the finishing touches on the system, I reflected on what just happened.
It's Not About Code Generation
Yes, AI wrote probably 100% of the code. But that's like saying a book is just words. The code was the least interesting part.
What AI really provided was:
A thinking partnership for problem decomposition
Domain expertise on demand
Implementation speed that let me focus on design
A patient collaborator for endless "what if" explorations
The New Development Paradigm
We're in a fundamentally new era:
Old Way: Think → Design → Implement → Debug → Ship (Linear, slow, phase-gated)
New Way: Think WITH AI → Rapidly prototype → Test assumptions → Iterate through dialogue (Conversational, fast, blurred phases)
The biggest shift? What's possible for one person. Five years ago, this project would needed atleast:
A PE expert
A web scraping specialist
An ML engineer
A data engineer
Today? One motivated person with AI as a partner builds it in a weekend.
The Principles That Emerged
Through this build, several principles crystallized:
1. Embrace Problem Asymmetry
Different sides of a problem need different solutions. Companies needed real-time research. Funds needed pre-indexing. Don't force symmetry where it doesn't exist.
2. The Last Mile Matters Most
A perfect matching algorithm that produces "Match Score: 87" is worthless. Actionable intelligence that explains its reasoning changes behavior. I spent as much time on report generation as on matching and that was the right choice.
3. Hybrid Architectures Win
Vectors for semantic similarity
SQL for hard constraints
LLMs for nuanced analysis
Each tool doing what it's best at. Smart orchestration is key.
4. AI Scales Judgment, Not Just Tasks
The system doesn't replace PE professionals. It gives them superpowers. They can evaluate every potential buyer, understand strategic fit deeper, approach funds with tailored positioning. We're scaling human judgment to superhuman scope.
What This Means for You - The Challenge
Here's my challenge to you: pick a problem in a domain you know nothing about.
Something that seems impossibly complex. Give yourself a weekend. Use AI as your reasoning partner and pair programmer.
Build something that shouldn't be possible for one person to build in 48 hours.
Not because it'll be perfect. It won't be. But because the process will expand your conception of what's possible.
I built a PE fund matching system with zero private equity knowledge. It works. It could genuinely help companies find buyers. More importantly, building it taught me that we're not just getting better tools, we're getting cognitive superpowers.
What domain expertise have you always wished you had? What problem have you wanted to solve but felt unqualified to tackle? That feeling of being unqualified? That's not a bug anymore. It's a feature. It means you'll approach the problem with fresh eyes and AI as your guide.
That's your next weekend project. And with AI as your partner, you're more qualified than you think.
P.S. - I've built systems before with engineering partners, but this was my first full end-to-end solo build of this complexity. Multiple data sources, different processing pipelines, intelligent matching, report generation, all in one weekend. If I can do it, so can you.